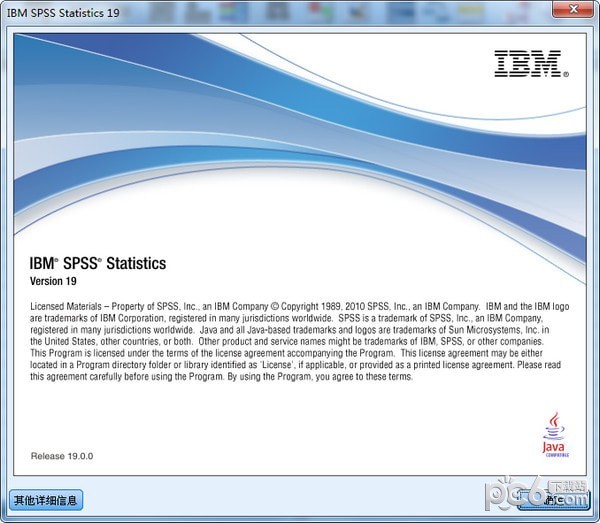
IBMSPSSStatistics19是IBM在收购SPSS公司后发布的一款统计分析软件的最新版本。这款软件面向的行业应用人员广泛,包括但不限于社会科学、医疗保健、金融、市场研究等众多领域。它提供了丰富的统计分析功能和方法,帮助用户从数据中提取洞见,支持研究和决策过程。IBMSPSSStatistics19作为一款成熟的统计软件,拥有用户友好的界面和强大的数据分析能力。它支持数据导入/导出多种格式,如Excel、CSV等,并允许用户进行复杂的数据操作和清理。该软件提供了全面的统计分析方法,包括描述统计、推断统计、回归分析、方差分析、聚类分析、因子分析等,以及高级数据建模和预测技术。
安装破解方法
将多下软件园分享的spss19安装包解压出来;
首先安装主程序;
安装好了以后,来到开始菜单,找到spss,它一般在所有程序--ibm spss statistics中
右键单击该快捷方式,在打开的右键菜单中,选择【属性】
找到安装的起始位置,【打开文件所在位置】
后将之解压出来的【spss19.0补丁】解压,复制原程序路径中,然后点击确定覆盖。
弹出是否替换文件,这里要选择【全部选是】
完成破解补丁覆盖后即可完成破解!
SPSS统计分析软件使用说明
一、输入数据
我们先来输入变量X的值,请确认一行二列单元格为当前单元格,弃鼠标而用键盘,输入第一个数据0.84;
请注意:在回车之前,你输入的数据在数据栏内显示,而不是在单元格内显示,现在回车,当前单元格下移,变成了二行二列单元格,而一行二列单元格的内容则被替换成了0.84;其次,第一行的标号变黑,表明该行已输入了数据;第三,一行一列单元格因为没有输入过数据,显示为“.”,这代表该数据为缺失值。用类似的输入方式,我们将患者的血磷值输入完毕,并将相应的变量GROUP均取值为1;
从第12行开始输入健康人的数据,并将相应的GROUP变量取值为2。最终该数据集应该有24条记录。
二、保存数据
选择菜单File==>Save,由于该数据从来没有被保存过,所以弹出Save as对话框;
单击保存类型列表框,可以看到软件所支持的各种数据类型,有DBF、FoxPro、EXCEL、ACCESS等,这里我们仍然将其存为自己的数据格式(*.sav文件)。在文件名框内键入Li1_1并回车,可以看到数据管理窗口左上角由Untitled变为了现在的变量名Li1_1。
为什么这里的对话框会出现汉字?是这样的,需要从编程的角度来解释:该软件在 弹出该对话框时会调用Windows系统的公用函数,由于我们用的是中文Windows系统,所以调用出来的就是中文。
三、分析数据
录入完数据后,你可以先进行基础的数据统计--描述性统计。然后根据你的数据结果再看是否需要相关回归或者其他分析。这款软件里面的描述统计主要在analyze——descriptive里面,其中有描述统计、频数统计、交叉分析。
描述性统计分析是统计分析的第一步,先选择analyze,你就能看到descriptive,然后鼠标再选Descriptive 菜单中,最常用的是列在最前面的四个过程:Frequencies过程的特色是产生频数表;Descriptives过程则进行一般性的统计描述;Explore过程用于对数据概况不清时的探索性分析;Crosstabs过程则完成计数资料和等级资料的统计描述和一般的统计检验
先选择analyze,---再选descriptive
打开任意的分析窗口后,你把想分析的数据选入,可以一起按鼠标左键选中按中间按钮加入,然后选择单击后弹出Statistics对话框,用于定义需要计算的其他描述统计量。你可以分析均数(Mean)、中位数(Median)、众数(Mode)、总和(Sum)等等。 然后还可以点Charts对话框,选择直方图、饼图等来绘图。都确定好后,选择单击Continue钮 ,然后选择OK。就可以了。直接就会有输出结果。
你可以先看看描述性统计的结果,有没有什么缺失值或者不符合实际的数据出现。要是有,你需要纠正数据,再用描述统计进行分析。
四、直接定义新变量
大多数情况下我们需要从头定义变量,在SPSS 10.0中,定义变量的操作界面和FoxPro等数据库非常相似,只需单击左下方的Variable View标签就可以切换到变量定义界面开始定义新变量。如Li1_1.sav的变量定义;
上部的两个文本框分别为变量值输入框和变量值标签输入框,分别在其中输入“1”和“克山病患者”,此时下方的Add钮变黑,单击它,该变量值标签就会被加入下方的标签框内。与此类似定义变量值“2”为“健康人”,最后按OK,变量值标签就设置完成。此时你做任何分析,在结果中都有相应的标签出现。如果你现在就想看效果,切换回Data View界面,然后选择菜单View==>Value Labels,怎么样,看到了吗?
缺失值 单击missing框右侧的省略号,会弹出缺失值对话框如下:
界面上有一列三个单选钮,默认值为最上方的“无缺失值”;第二项为“不连续缺失值保疃嗫梢远ㄒ?个值;最后一项为“缺失值范围加可选的一个缺失值”,文如其意,不用我多解释了吧。
以变量x为例:变量名为x,类型为Numeric,宽度为4,小数位数2位(因小数点还要占一位,故整数位只有一位),变量标签位为“血磷值”。右侧在图中未能看到的依次为Values,用于定义具体变量值的标签;Missing,用于定义变量缺失值;Colomns,定义显示列宽;Align,定义显示对齐方式;Measure,定义变量类型是连续、有序分类还是无序分类。
使用该窗口,我们可以一次定义许多新变量,不会象老版本那样一个一个的定义了。
由于是英文软件,变量名采用中文会有潜在的冲突(100%的兼容性是不存在的,典型的例子就是微软公司的产品)。
对于喜欢搞点花样的用户,这里有必要介绍一下这款软件中标签和缺失值的定义方法:
标签 和老版本不同,现在变量标签和变量值标签被分开设置,变量标签就在Label框中直接输入,变量值标签则在它右侧的Value框定义。
SPSS统计分析软件特色
1.数据处理能力:IBMSPSSStatistics19能够处理大规模数据集,支持数据清洗、转换和重塑,以便进行深入的统计分析。
2.全面的统计方法:软件包含多种统计分析方法,适用于不同类型的研究设计和数据分析需求,帮助用户选择合适的统计测试和模型。
3.高级分析工具:除了传统的统计分析,IBMSPSSStatistics19还提供了高级分析工具,如机器学习算法、神经网络等,支持用户进行复杂的数据建模和预测。
4.易于使用:软件界面直观,即使用户没有深厚的统计背景,也能容易地使用该软件进行数据分析。
5.可定制性和扩展性:IBMSPSSStatistics19允许用户自定义分析流程和报告格式,同时也支持通过插件扩展软件功能。
6.强大的报告和可视化工具:能够生成高质量的统计报告和图表,帮助用户清晰地表达分析结果。
IBMSPSSStatistics19的发布标志着IBM在统计分析软件领域的又一次重要进展,它继续为用户提供强大的数据分析工具,以支持他们在各个行业中的研究和决策工作。
 快捷导航
快捷导航